| Предыдущий раздел |
Следующий, очень интересный вопрос, возникающий при проектировании
церковно-славянской КШС -- как снабдить ее мощной системой надстрочных знаков
церковно-славянского языка? Десяток акцидентных надстрочников, десяток букво-титл
для позднего извода и теоретически полсотни букво-титл -- для древнего ЦС. Все
это над буквами, имеющими как нормальную высоту, так и выступающие части (наподобие
![]() или
или ![]() ),
с варьирующейся шириной (
),
с варьирующейся шириной (![]() ,
,
![]() с одной
стороны и
с одной
стороны и ![]() ,
,
![]() -- с другой).
Ну и, конечно, что может предложить нам для этого Unicode.
-- с другой).
Ну и, конечно, что может предложить нам для этого Unicode.
Полнолигатурный метод. А как поступают с надстрочниками в Европе? Там ведь очень много букв с диакритикой. С диакритикой в Европе поступают просто и надежно. Для каждой из возможных комбинаций "буква+диакритик" в кодировке отводится персональная позиция, где и рисуется буква с надстрочником единым графическим знаком. Возможных комбинаций оказывается не так уж много. Для Западной Европы -- порядка десятка на язык, так что все западноевропейские комбинации можно уместить в пределах верхней 128-символьной половины страницы; для современной Греции -- побольше, но у нее своя кодовая страница, так что место есть и там. А вот греческое политоническое письмо уже требует отдельной кодовой страницы, посвященной только ему.
Давайте попробуем применить этот способ к церковно-славянскому языку. Интуиция, правда, подсказывает, что комбинаций "буква+надстрочник" здесь будет гораздо больше. Сделаем поэтому оценку необходимого количества кодового пространства.
Новоцерковно-славянский язык. Для точной оценки необходимо пересмотреть большое количество имеющихся текстов, либо тщательно проанализировать грамматику языка, в том числе и неявные правила. К счастью, многими разработчиками ЦС шрифтов эта работа уже делалась, и полученные таким образом независимые результаты более-менее совпадают. С учетом знаков пунктуации, основных символов и всех комбинаций с надстрочниками требуется порядка 500 знакомест. То есть, две 8-битных кодовых страницы без латиницы и под завязку.
Древний ЦС. Здесь точно оценить количество всех возможных комбинаций сложнее, поэтому я буду давать оценку сверху. 60-70 букв строчного регистра, 60 -- заглавного. Чуть больше десятка акцидентных надстрочников, и... реально десятка два, но теоретически -- все 6-7 десятков букво-титл. Все надстрочники могут встречаться, вообще говоря, над всеми буквами. Итого: (60+60)*(10+20)=3600, (70+60)*(10+70)=10400. Короче, от 4 до 10 тысяч. Это, повторю, оценка сверху, ибо точную оценку я дать не готов, для этого мне нужно больше информации.
Рассмотрению способов размещения такого количества знаков в кодовом пространстве шрифтов у меня посвящен отдельный раздел, поэтому оставим пока этот вопрос. Давайте как-то назовем сам метод полной реализации всех комбинаций.
Я хочу ввести одно определение. Лигатурой будем называть
самостоятельный цельный символ, изображение которого состоит из основной буквы
и надстрочного знака, в самом оптимальном их расположении. Определение не совсем
корректное, ибо под лигатурой традиционно понимается несколько иное. Однако
мне не удалось найти для описанного объекта официального термина. Самые близкие
к нему понятия -- лигатура и композит. Лигатура в традиционном смысле этого
слова -- это цельный самостоятельный символ, изображающий несколько основных
букв в каком-то специальном их объединении. Именно букв, но не буквы и надстрочника.
Например: ![]() .
Понятие лигатуры относится чаще всего к кодировке, но может применяться и ко
шрифту (лигатурная подстановка в OpenType-шрифте). Композит, в свою очередь
-- это символ внутри шрифта, изображение которого составлено из частей других
символов, чаще всего основной буквы и какого-то надстрочника. Казалось бы, термин
"композит" -- именно то, что нам нужно. Но это не так. Композит --
понятие внутришрифтовое, относящееся к тому, как устроен конкретный набор контуров
конкретного символа конкретного шрифта. Чтобы сэкономить занимаемое описанием
контуров место в шрифте, часто повторяющиеся контура представляются только один
раз, а все последующие их использования заменяются ссылками на оригинал. Если
мы делаем символ aacute, мы берем ссылку на контур латинской a и ссылку на контур
символа acute, размещаем их в нужном расположении и получаем композит. А могли
бы просто нарисовать эти контура еще раз. Короче, композиты -- дело внутришрифтовое,
а нам необходимо понятие, относящееся к кодировке. Официальный термин лигатуры
в этом смысле ближе, ибо а) лигатура в моем понятии -- термин, относящийся к
кодировке, и дизайнер обязан реализовывать все предписываемые лигатуры, иначе
текст без некоторых лигатур будет отображаться некорректно; б) лигатурный символ
в моем смысле способен, подобно официально понимаемой лигатуре, полностью преобразить
изображения исходных букв. Например, раздвинуть дуги в
.
Понятие лигатуры относится чаще всего к кодировке, но может применяться и ко
шрифту (лигатурная подстановка в OpenType-шрифте). Композит, в свою очередь
-- это символ внутри шрифта, изображение которого составлено из частей других
символов, чаще всего основной буквы и какого-то надстрочника. Казалось бы, термин
"композит" -- именно то, что нам нужно. Но это не так. Композит --
понятие внутришрифтовое, относящееся к тому, как устроен конкретный набор контуров
конкретного символа конкретного шрифта. Чтобы сэкономить занимаемое описанием
контуров место в шрифте, часто повторяющиеся контура представляются только один
раз, а все последующие их использования заменяются ссылками на оригинал. Если
мы делаем символ aacute, мы берем ссылку на контур латинской a и ссылку на контур
символа acute, размещаем их в нужном расположении и получаем композит. А могли
бы просто нарисовать эти контура еще раз. Короче, композиты -- дело внутришрифтовое,
а нам необходимо понятие, относящееся к кодировке. Официальный термин лигатуры
в этом смысле ближе, ибо а) лигатура в моем понятии -- термин, относящийся к
кодировке, и дизайнер обязан реализовывать все предписываемые лигатуры, иначе
текст без некоторых лигатур будет отображаться некорректно; б) лигатурный символ
в моем смысле способен, подобно официально понимаемой лигатуре, полностью преобразить
изображения исходных букв. Например, раздвинуть дуги в ![]() для помещения над ней нужного надстрочника, либо подпилить верхний хвостик у
для помещения над ней нужного надстрочника, либо подпилить верхний хвостик у
![]() для размещения
над ней придыхания с ударением:
для размещения
над ней придыхания с ударением: ![]() .
Поэтому я буду использовать именно его.
.
Поэтому я буду использовать именно его.
Итак, цельные символы-комбинации "буква+надстрочник" в нашем шрифте называются лигатурами. Тогда рассматриваемый метод реализации надстрочников (когда в шрифт помещаются все возможные комбинации-лигатуры) логично назвать полнолигатурным. Метод наиболее надежный, но чрезвычайно тяжелый, ибо, помимо необходимости как-то разместить всю массу лигатур внутри кодового пространства, эти самые лигатуры дизайнеру необходимо прорисовать. Путь даже при этом он будет пользоваться готовыми контурами -- все равно, работы много. Собственно поэтому чистая полнолигатурная реализация церковно-славянской КШС мне не встречалась ни разу, вряд ли где-то существует, да и, вообще говоря, никому не нужна в свете других методов. Мы рассматриваем ее лишь как пограничный случай, ибо на практике она обязательно встречается в составе комбинированных методов.
Следующий класс методов реализации надстрочников -- составные
надстрочные символы (Combining diacritics), или накладные надстрочники.
Почему у нас так много лигатур? Из-за того, что мы перемножили количество основных
символов на количество возможных надстрочников. Что, если кодировать символ
с надстрочником не одним, а двумя кодами: кодом основного символа и следующим
за ним кодом надстрочника? Присвоить им разные кодовые позиции и обязать систему
рисовать ![]() ,
если она встретила код обычной
,
если она встретила код обычной ![]() ,
а вслед за ней -- код прямого ударения
,
а вслед за ней -- код прямого ударения ![]() .
.
Идея хорошая, но в полной мере и в самом общем случае реализуема только переделкой растеризатора, либо написанием специализированного текстового процессора с нуля. Но это -- в полной мере. Если не требовать крайностей, идея вполне плодотворна.
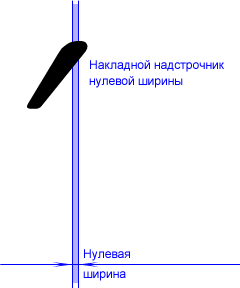
Метод накладных надстрочников нулевой ширины. Этот метод почти не требует переделки системы, обходясь лишь средствами шрифтов.
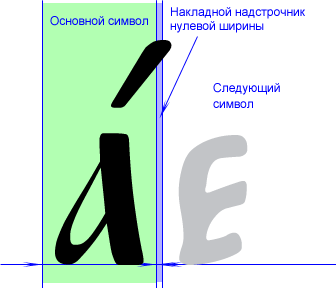
Основные символы создаются как обычно. Отличие состоит в устройстве символов накладных надстрочников. Каждый такой символ имеет в идеале нулевую логическую ширину (правая граница символа совпадает с левой), а рисунок самого надстрочника сильно смещен влево (для правосторонних надстрочников), или вправо (для левосторонних), или расположен по центру для центральных. Рассмотрим, к примеру, правосторонний надстрочник. Мы набираем основной символ, за ним надстрочник. При этом рисунок надстрочника оказывается над набранным перед этим основным символом (за счет сильного смещения влево), а курсор не меняет своего положения (за счет нулевой ширины), так что следующий символ появляется после надстрочника там же, где он должен был бы быть без него. Вот схема для случая правостороннего надстрочника:
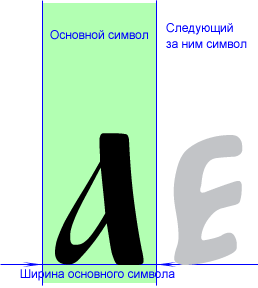 |
+ |
 |
||
|
=
 |
||||
Как уже говорилось, в идеале накладной надстрочник должен иметь нулевую ширину, дабы следующий за ним символ появлялся непосредственно за основным. Такое, правда, переваривают далеко не все программы и драйверы принтеров. На практике приходится оставлять надстрочнику ширину в 1-2 единицы (units), что составляет примерно от нескольких сотых до нескольких тысячных средней ширины буквенного символа. Почему-то такое мизерное отделение значения ширины надстрочника от точного нуля спасает положение в большинстве случаев, и не сказывается при этом визуально в сколько-нибудь заметном увеличении межсимвольного интервала после акцентированной буквы. На рисунке ширина надстрочника сильно увеличена, дабы читатель мог увидеть суть идеи. Реально же рассмотреть ее на разрешении монитора нельзя.
Таким образом, этот метод правильнее было бы назвать методом накладных надстрочников почти нулевой ширины, но это звучит слишком длинно. Метод этот не нов и не является специфичным только для церковно-славянского языка. Так делаются накладные надстрочники во многих фирменных шрифтах, и на сегодня подавляющее большинство программ корректно обрабатывает все эти фокусы с обратными смещениями рисунка и нулевыми ширинами. Повторюсь, устойчивость шрифта можно сильно повысить, если делать нужные ширины почти нулевыми вместо строго нулевых, оставляя зазоры в 1-2 единицы.
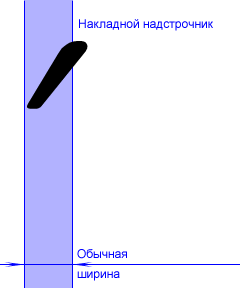
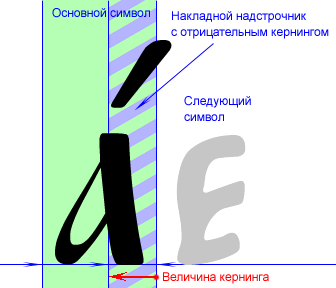
Накладные надстрочники по методу кернинга. Это вариация предыдущего метода. Основные символы не имеют никаких особенностей, а у накладных надстрочников оставляется вполне нормальная ширина и рисунок не смещается сильно за границы. Вместо этого задействуется механизм кернинг-пар.
Для примера рассмотрим правосторонний надстрочник. Пусть по смыслу он может группироваться с буквами "а", "б" и "в". Тогда следующие кернинг-пары шрифта: ("а", надстрочник); ("б", надстрочник); ("в", надстрочник) -- устанавливаются в шрифте равными минус ширине символа надстрочника. Если включить кернинг в тексте, эти манипуляции дадут тот же результат, что и предыдущий метод: будучи поставленным после, скажем, "а", рисунок надстрочника сильно сместится влево (за счет кернинга), оказавшись над основным символом; с другой стороны, следующий символ появится на своем законном месте, ибо вполне ненулевая ширина надстрочника между ними в точности погасится отрицательным значением кернинга, который для данной пары, повторю, мы установили равным минус ширине надстрочника.
|
+ |
 |
||
|
=
 |
||||
Этот метод требует от текстового процессора поддержки кернинга. Метод может послужить альтернативой надстрочникам нулевой ширины, если какая-то система плохо воспринимает очень узкие символы или сильное смещение рисунка за границы символа.
Метод лигатурных подстановок (ligature substitutions) с применением возможностей OpenType. OpenType -- это новый формат шрифтов, разработанный Microsoft. Анонсирован он был сравнительно давно (в середине 90-х), но лишь в 2000 году получил какую-то поддержку, да и то лишь в очень малой части своих возможностей. Необходимый нам объем стандарта на сегодня поддерживается, по моим сведениям, лишь в Adobe InDesign. Тем не менее имеет смысл сказать пару слов об этом весьма перспективном формате.
Одна из возможностей формата OpenType -- возможность описать внутри шрифта таблицы лигатурных подстановок (Glyph substitution tables, GSUB). Суть в следующем. Спецификация позволяет заменять изображения нескольких идущих подряд символов на новое, характерное только для данной последовательности. Например:
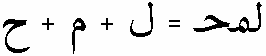 |
Очевидно, эту возможность можно использовать для церковно-славянских текстов. Достаточно определить лигатурные подстановки для пар основных символов и накладных надстрочников -- и редактор с поддержкой этой части OpenType сделает все остальное. Именно редактор с поддержкой. Ведь просто определить таблицы внутри шрифта мало. Необходимо, чтобы приложение озаботилось наличием и содержимым этих таблиц.
На сегодняшний день мне известно только одно dtp-приложение с поддержкой OpenType GSUB. Это Adobe InDesign.
Комбинированные методы. На самом деле, ни одна реальная КШС не использует перечисленные методы в чистом виде. Наилучшие результаты с точки зрения качества, надежности и простоты получаются, если использовать смесь методов. Например, накладные надстрочники для большинства пар вместе с лигатурами для "тяжелых случаев". Лигатуры улучшают внешний вид текста в необходимых случаях. Или, наоборот, полное лигатурирование для самых распространенных надстрочников, и накладные надстрочники для редких букво-титл. Это позволяет избежать слишком большого количества лигатур, ведь основная их часть при действительно полном лигатурировании будет использоваться крайне редко. В обзоре реальных КШС мы вернемся к комбинированным методам и рассмотрим конкретные примеры.
| Предыдущий раздел |